Nous avons développé et testé un mécanisme de navigation inspiré de l'hippocampe du cerveau des mammifères, qui a l'avantage d'être robuste et tolérant aux erreurs. Ce mécanisme permet de placer des 'cellules de lieux' caractérisant des régions de l'espace, l'ensemble de ces cellules formant une carte de l'environnement topologique mais non topographique, permettant une tolérance à la dérive.
Dans ce modèle, chaque cellule de lieux caractérise une position unique de l'espace, et indique la direction pour atteindre les cellules voisines. Les cellules de lieu sont placées lorsque l'on change de direction, permettant une discrétisation adaptée de l'environnement. Nous avons pu tester ce modèle sur un agent RI, qui a l'avantage de ne pas avoir de notion a priori de l'espace, mais également dans un environnement réel, en utilisant une caméra.
Nous avons dans un premier temps testé le système de navigation sur un agent RI issu de mes travaux de thèse. L'agent est placé dans un environnement bien plus grand que ce que sa mémoire spatiale peut intégrer. Son système interactionnel définit une préférence pour manger la nourriture dans l'ordre rouge-vert-bleu. Il dispose également d'un mécanisme implémentant une forme de curiosité le poussant à explorer les directions inexplorées autours des cellules de lieu. Notons que ce test vise uniquement à tester les algorithmes de construction et de navigation, la reconnaissance des lieux est ainsi hardcodée pour ne pas fausser les résultats avec des détections erronées.
Après un apprentissage dans un environnement de faible dimensions, l'agent est placé dans le grand environnement. Son mécanisme de curiosité le pousse à explorer son environnement, jusqu'à ce qu'une instance de chaque point de nourriture soit trouvé. L'agent passe ensuite d'une proie à une autre, en utilisant le graphe de navigation pour se diriger d'un point à un autre.
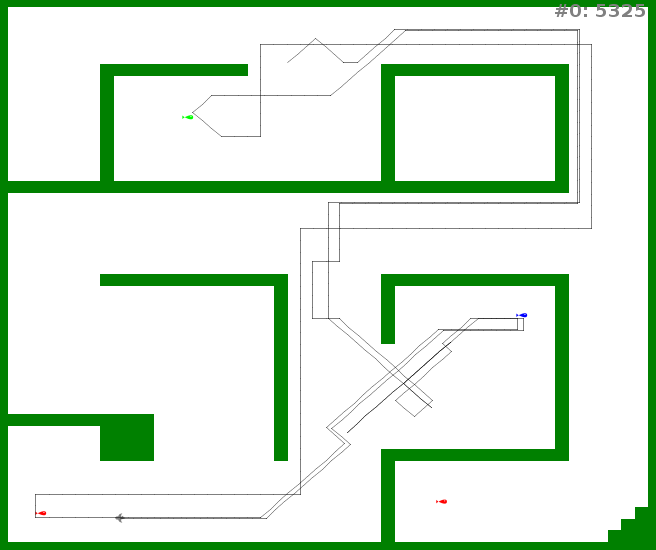
Construction du graphe de navigation pendant l'exploration. L'agent débute en haut à gauche : il découvre la salle avec le point de nourriture vert, mais la néglige. Plus tard, il découvre le point de nourriture rouge. Il interagit donc pour manger, puis se dirige immédiatement vers le point de nourriture vert avant de reprendre son exploration. Il finit par trouver le point de nourriture bleu. À partir de ce moment, l'agent va naviguer entre ces points pour manger la nourriture dans le bon ordre.
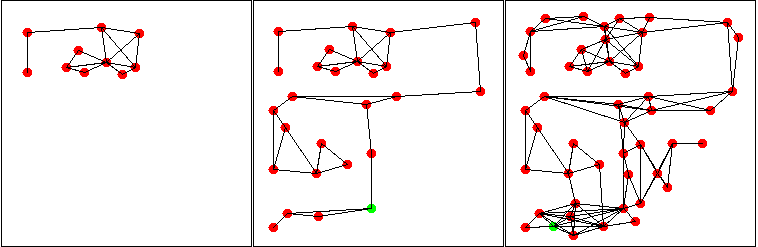
Nous avons ensuite testé le système en environnement réel, avec un système de reconnaissance utilisant une détection de points d'intérêts visuels. On effectue le tour d'une pièce avant de revenir au point de départ. Le système place quatre cellules de lieux pour caractériser le chemin parcouru. On observera sur le graphe que la première cellule a été reconnue, permettant de la connecter à la quatrième. On notera toutefois qu'à cause de la dérive, les cellules ne sont pas correctement alignées. Cependant, comme chaque cellule de lieu définit son propre référentiel, les cellules 1 et 4 indiquent la bonne direction pour atteindre ses voisines.
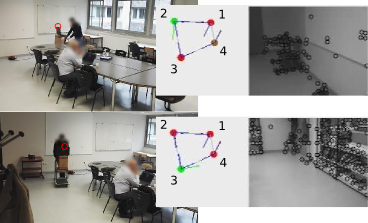
Ce mécanisme, bien qu'efficace et tolérant à la dérive, est moins robuste dans un environnement redondant. Nous avons alors envisagé un système utilisant à la fois la reconnaissance visuelle et l'intégration de chemin par un mécanisme d'odométrie visuelle inspiré des Cellules de Grille.