The developmental agents studied during my thesis showed that it was possible to construct a model of the environment based only on the regularities observed through the enaction of sensorimotor schemes. After a certain learning period, this model becomes capable of ‘representing’ the surrounding environment in an egocentric frame of reference, and of tracking and updating this representation as the agent moves, defining a form of object permanence. The agent then characterises its surrounding environment in the form of a context of affordances located in its extra-personal space, which can be exploited to generate behaviours that satisfy its motivational principles.
However, this spatial memory mechanism has only been studied in static environments or, as in this case, in environments where movements are predictable. In order to interact with other agents, a developmental agent must develop the ability to detect these agents and predict the most probable behaviours in order to act accordingly. The work presented here concerns the study of the emergence of the ability to predict behaviours of another agent. The principle is as follows: an agent acts according to the affordances that surround it. Thus, if an agent can know the environmental context from the point of view of another agent, and if it knows its behavioural preferences, then it can predict the most probable movements of this other agent. This principle is therefore based on the assumption that the behavioural model of this other agent is based on principles similar to those of the developmental agent, that ‘projects’ its own functioning onto the other agent.

This principle requires several processing steps:
- being able to detect an unpredictable moving object,
- being able to locate a moving object in space,
- being able to track a moving object over several consecutive steps,
- being able to infer the behavioural preferences of the moving object,
- predicting the probable behaviour(s) of the moving object,
- generating behaviours exploiting these predictions.
This work was described in a trilogy of papers presented at conferences ICDL2022, ICDL2023 and ICDL2025.

I Detecting a mobile object in the environment (ICDL 2022)
Our learning mechanisms are based on the ability to predict the outcome of a sensorimotor scheme (success or failure) based on previously enacted sensorimotor schemes. From an external perspective, affordance can be defined as the element of the environment that enables the success (or failure) of an interaction i, with the prediction of the outcome of i being defined by the interactions whose enaction reveals the presence of this affordance. The interactions that enable the prediction of interaction i form the “Signature” of i. This signature makes it possible to define, based on the enacted interactions, the certainty of success or failure of the interaction as a value between 1 (absolute certainty of success) and -1 (absolute certainty of failure).
Detecting a mobile object is more complex than it seems: the agent can detect the presence of an affordance, but if it moves, the interaction will still fail. Furthermore, the affordance may afford its interaction from several positions, depending on its movements. These particularities mean that the signature mechanisms used until now fail to integrate these objects in the agent's environment model.
The proposed solution came from an observation about the certainties measured by signatures of interactions: although these certainties were always negative and close to -1, because the presence of the affordance leads to a failure most of the time, the fact that the interaction can only succeed if the affordance is present allows for at least a partial construction of the signature. Thus, the certainty of success, although still negative, is systematically lower, in absolute value, when the affordance is present (typically between -0.8 and -0.9 when affordance is present and between -0.9 and -1 when it is absent).
The following principle was then proposed: we start with the classical learning process. After a certain number of interaction attempts, during which the average prediction is measured, we add the following rule:
- if the interaction succeeds, then the signature is reinforced as a success,
- if the interaction fails AND the prediction is below average, the signature is reinforced as a failure,
- if the interaction fails AND the prediction is above average, the signature is not modified.
The elimination of cases of failure in the (supposed) presence of the affordance allows the emergence of signatures of interactions afforded by mobile objects. The figures below show the prediction profiles for interactions afforded by static and dynamic elements.
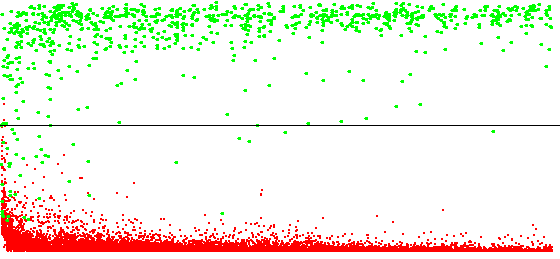
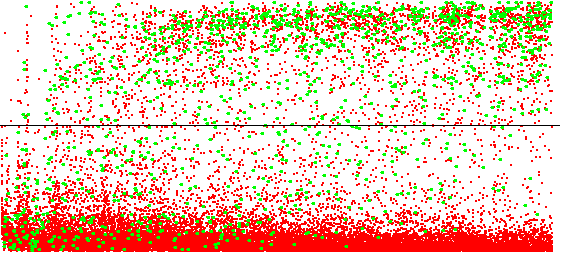
Since the different movements of a moving object can have different probabilities, it became necessary to separate the different contexts affording an interaction, i.e. the different positions from which the interaction can be enacted. I therefore proposed a signature model defining several competing “sub-signatures”. After an initial learning phase in which the “sub-signatures” are reinforced identically, the competition system is activated: if the interaction is successful, only the sub-signature with the highest certainty is reinforced as a success. If it fails, all sub-signatures are reinforced as a failure. This principle leads each sub-signature to specialise in a certain context affording the interaction. In order to accelerate the specialisation process, a sub-signature whose predictions display a certain level of reliability will eliminate the context it characterises from the other sub-signatures. The following figure shows an implementation of this signature model based on formal neural networks.

When a sub-signature shows a certain level of reliability, the success and failure ratio can be measured when affordance is assumed to be present. This makes possible to define the probability (information that is independent of the certainty) specific to each position of the moving object, and thus characterise the probability of each possible movement.

Initially, the agent is only guided by the learning mechanism, which seeks to test interactions with a low probability (in absolute value) of success/failure. When signatures begin to provide high certainty, the exploitation mechanisms gradually replace the learning mechanism (although the latter becomes active again if the environment changes sufficiently to make signatures obsolete).
Signatures are implemented with sets of 7 competing formal neurons. The agent has a set of 6 interactions, called 'primitive interactions': move forward one step, bump, eat, slide on a soft object, turn left and right 90°. The visual system allows three colours (red, green and blue) to be observed at one of 15x9=135 positions in the visual system. These positions are unknown to the agent, and the regular grid distribution makes it easier to read the signatures. The visual system can thus generate 405 visual perceptions. This visual information cannot be dissociated from the movement that generate it, namely the movement generated by the enactment of a primary interaction. These visual perceptions are therefore associated with primary interactions (except for bumping, which does not generate movement) to form a set of 2025 secondary interactions. These interactions therefore take the form of ‘move forward and see a blue element in position #23’ or ‘turn right and see a green element in position #64’. These secondary visual interactions bring the number of interactions available to the agent to 2,031.
In order to make it easier to read and analyse the context of enacted interactions and signatures, the list of interactions is organized as follows: the six primary interactions are represented at the bottom with six small squares. Visual interactions are grouped according to their associated primary interaction to form five groups. Within each group, interactions are organised to match to their actual position in the field of vision and coloured according to their associated colour. These groups thus form a colour image representing the visual context in front of the agent.
We therefore initially allow the agent moving in its environment (figure above) to discover regularities in its interactions and construct signatures. The signatures of the interactions bump and slide, which are afforded by static objects, appear in the first 5,000 decision cycles, a duration similar to those observed in static environments. As these interactions are only afforded by a single context, only one of the signature's neurons is exploited, the others retaining weights close to 0. The bump interaction is afforded by the detection of a green object in front of the agent (regardless of the movement performed by the agent), but also by the previous enaction of bump interaction, both of which characterise the presence of a green wall in front of the agent. This example shows that signatures can gather all the sensory modalities that characterise an affordance. The sliding interaction is associated with the observation of a red object in front of the agent, characterising the presence of red algae. The two signatures define a context with a probability greater than 90%, confirming that the affordance does not move.

The signatures of move forward and eat interactions take longer to emerge: approximately 50 000 decision cycles are required, mainly because the interaction can fail even when affordance is present. We can notice that the signature of move forward interaction has an output weight W close to -1: it is therefore an interaction whose affordance, designated by the signature, prevents its enactment. In the case of eat interaction, up to five contexts are defined, each corresponding to a position of the fish relative to the agent which, if the fish moves in the right direction, allows the interaction to succeed. Note that since the fish cannot be below the agent after taking a step forward, the ‘below’ context is not present in the first three lines of the signature (groups of interactions related to move forward, eat and slide). The contexts characterising the presence of a fish in front of the agent are defined with a probability of success of around 25%, while the peripheral positions are close to 19%, which is consistent with the fact that fish can be blocked by a wall. In the case of move forward interaction, up to seven contexts are defined. We find contexts linked to the presence of a green element and a red element in front of the agent, defined with a high probability indicating that these objects are static, and the five contexts linked to a blue object (the fish) with probabilities close to those defined by the eat interaction signature. It is therefore possible to distinguish between moving and static objects based on their probabilities.

Visual interactions also have their own signatures. In the case of visual interactions involving green and red colours, a single neuron defines a context. This is because green and red objects in this environment are static. By analysing the difference between the position associated with a visual interaction and the position of the elements designated by its signature, we can observe that the signature encodes the movement produced by the primary interaction. Thus, for the forward interaction, the signature designates an element of the same colour, but located one step forward. For the 90° turn interactions, we observe a rotation of the field of vision centered on the agent.

The signatures of visual interactions related to the colour blue designate up to five contexts, corresponding to the five possible movements of blue objects. However, the movement generated by the primary interaction remains visible.

The ability of signatures to encode the movement of a primary interaction is the basis of the mechanism for detecting distant affordances described below.
II locate a moving object in space (ICDL 2023)
The localisation of distant affordances is based on a property of signatures of interactions: a signature refers to interactions enabling the detection of an affordance, interactions that may have their own signature. Thus, if we consider the interactions {jk} designated by a signature of an interaction i, associated with the same primary interaction j, then the set of signatures of these interactions designates an element which, after enacting j, is likely to afford interaction i. Thus, this ‘projection’ of the signature designates the affordance of i, but at a position that can be reached by enacting interaction j. By performing this projection recursively, it becomes possible to designate an affordance that can be reached by performing a certain sequence of interactions.

In the case of an interaction afforded by a mobile object, the signature consists of several sub-signatures. A projection would lead to an explosion in the number of projected contexts. We therefore proposed using the probabilities of the sub-contexts to filter and retain only the most probable projections. This principle of projection is illustrated below.

Once the signature projections have been obtained, it becomes possible to detect distant affordances and locate them through sequences of interactions. Since each interaction can be ‘linked’ by multiple sequences, the same mobile affordance will be located by multiple sequences. These sequences make it possible to characterise the different possible positions of the mobile object at the next instant. The figure below shows an example of distant affordance detection.

Static affordances, designated by sub-signatures with a high probability, are located by a small number of sequences (sometimes with a single one). These affordances are recorded by the agent's space memory. The position of these affordances is then characterised by a list of structures called Places, giving the distance and the first interaction of the sequence leading to the affordance. Mobile affordances are detected by a set of sequences characterising the different possible movements. As the space memory has not yet been tested with mobile affordances, these affordances will not be recorded.
III Tracking a moving object over several consecutive steps (ICDL 2023)
In order to analyse the behaviour of another agent, it is important to be able to recognise an agent instance over several simulation steps and to be able to observe its movements, particularly in the reference frame of its immediate environment. The hypothesis is therefore that if the developmental agent can know the affordance context of another agent and can observe its movements, then it becomes possible to determine the behavioural preferences of that other agent, in particular which affordances it tends to move towards and which affordances it tends to avoid.
This hypothesis implies two specific constraints. First, the agent must have interactions that allow it to detect the presence of all affordances likely to influence the behaviour of the other agent. Then, the other agent must use a behavioural model similar to those of the developmental agent, so that it can use its own behavioural model to compare what it would have done in similar situations and, by analysing the differences, deduce the behavioural preferences of the other agent.
To obtain the context from another agent's point of view, we will exploit the properties of the space memory: this structure can update the affordance context around the agent as it moves by enacting interactions. We will therefore be able to simulate a sequence leading to a mobile affordance and obtain the context of affordances ‘observable’ from this position. However, two problems must be solved:
- First, a mobile affordance is located by a set of interaction sequences. This problem is easily solved by the fact that we only need the distance of the affordances. Thus, we will compute the average of the distances of affordances obtained by simulating the different sequences.
- Next, the interaction sequences show the position from which the agent can interact with the affordance, rather than the position of the affordance itself. The solution chosen is based on interactions afforded by ‘negative’ affordances, i.e. those whose success is linked to the absence of the affordance. The hypothesis is that these negative affordances delimit a volume of space that must be empty, this volume having to be occupied, totally or partially, by the agent itself during or at the end of the enaction of this interaction. The interaction move forward illustrates this principle: the signature of this interaction indicates the volume in front of the agent that the agent will occupy during and after moving forward, with the presence of any object in this volume leading to the failure of the interaction. In continuous versions of the model, the signature designates a volume the size and shape of the agent's “hitbox” (the shape used by the environment's physics engine to manage collisions). We then exploit the fact that certain interactions are mutually alternative, i.e. the failure of one can lead to the success of another. In our example, the interactions move forward, bump, eat and slide are mutually alternative. If one of these interactions fails, one of the other three will be enacted instead. The fact that two interactions are mutually alternative implies that their affordances have a similar size and position. Thus, if the agent detects the presence of the bumping interaction, assuming that it can move forward, then it would occupy the same position as the object that affords bump. We therefore retain the following principle: if the agent detects a distant affordance of an interaction i located by a certain sequence s, if there is an interaction j afforded by a negative affordance and which is mutually alternative to i, then we can obtain the real position of the affordance of i by simulating the sequence [s,j].

Now that the affordance context of the mobile entity is known, it is necessary to observe this entity over several simulation steps in order to study its behaviour. To do this, we use sequences allowing to locate the affordance: some of these sequences begin with the interaction performed by the agent. Thus, it is possible to obtain a set of sequences locating the new position at time t+1 by filtering the sequences beginning with the enacted interaction and removing this first interaction from remaining sequences. A new detection allows the detection of mobile affordances. If certain sequences are common between those updated and those newly detected, then it is likely that the new entity is the same as the one detected at time t. Once the entity has been identified, any variations in distance that appear in the affordance context are observed. If at least one affordance has had a distance variation close to 1 (the displacement being in theory exactly of 1 interaction), then we can consider that the affordance has moved. It should be noted that the displacement is measured in an allocentric reference frame (since it is based on static elements in the environment), a first for our developmental agents, which until now have only used egocentric reference frames.

IV Infering the behavioural preferences of moving objects (ICDL 2023)
This mechanism is based on the assumption that the behaviour of the mobile entity uses a mechanism that is similar to the developmental agent, so that this decision-making mechanism can be projected onto the entity. The model is therefore limited to understanding agents whose complexity does not exceed that of the developmental agent, otherwise the latter may not be able to understand the causes of the other agent's actions. The idea here is to apply the agent's decision-making model to the mobile entity and analyse its movements in order to adapt the satisfaction values of the interactions.
The current decision models of our developmental agents are primarily reactive, and drive the agent to move closer to interaction affordances with a high satisfaction value, and stay away from interaction affordances with a negative satisfaction value. These model define a utility value to interactions allowing the agent to move closer to ‘interesting’ affordances, which determines the choice of the interaction to enact.

The developmental agent cannot know the interactions of the mobile entity. However, we can assume that, regardless of the movement made by this entity, its movement must bring it closer to ‘positive’ affordances or further away from ‘negative’ affordances. We can therefore define a utility value not for interactions, but for the change in position of the entity. Utility should normally always be positive, as the agent is assumed to follow its preferences.

Thus, if the utility value between two consecutive steps is negative, it means that the preferences are incorrect and must be modified. In the event of a correction, the following principle is applied: interactions of affordances that move closer have their satisfaction values increased, while interactions of affordances that move further have their satisfaction value decreased. The variation in value will depend on the distance of an affordance, as close affordances have more influence on the behaviour. In order to reduce the impact of incomplete observations of affordance contexts, the following rules are added:
- Values can only be corrected if the contexts before and after the movement contain the same affordances: the appearance or disappearance of an affordance can bias utility calculations.
- The correction will be inversely proportional to the distance of the entity: a distant entity will be more likely to perceive affordances that are not visible to the agent.
- The correction becomes weaker over time: this allows the satisfaction values to gradually stabilise and reduces the impact of incomplete observation of affordance contexts.
The test environment was modified to test the inference of satisfaction values. The fish are now controlled by a decision mechanism that depends on surrounding objects. As the current version of spatial memory does not include moving elements, we will only be able to test the inference of satisfaction values related to static objects. A fish is strongly attracted by algae (which it eats when it passes over them) and weakly repelled by walls. The satisfaction value of algae is set to 20 and that of walls to -2. The fact that fish react to algae motivated the addition of the “slide” interaction to the developmental agent's set of interactions. Without this interaction, algae, which can be passed through, is comparable to empty space for the agent. The agent would then have been unable to determine the causes of the fish's decisions. The fact that an agent needs to be able to detect the affordances of other agents is a strong constraint, but biologically plausible in the case of a predator evolving in the same environment as its prey.

For this experiment, the agent is equipped with a hard-coded space memory that reproduces the operating principles observed during my thesis work, in order to eliminate any bias related to an incomplete learning of this structure. A curiosity mechanism is implemented, which drive the agent to move towards the affordance, among those detected as mobile, that is the closest, increasing the chances of relevant and reliable observations. This mechanism exploits the sequences of interactions leading to these affordances by selecting the first interaction in these sequences. In the event of a negative utility observation with a consistent affordance context (same affordances), the satisfaction values of an affordance for a mobile element are updated as follows:

The values stabilise quickly, requiring fewer than 500 observations and updates. The table below shows a representative sample of tests and the obtained values. Note that since we only use the sign of the utility value, and since the positions are compared with each other, the satisfaction values can be multiplied by any positive constant. Therefore, only the signs and the ratio between the satisfaction values are important.

We can observe that the agent systematically assigns a positive value to elements that afford the slide interaction and a negative value to elements that afford bump interaction. Furthermore, the ratio between these two values rarely exceeds the interval [-20,-5], showing that these mobile affordances (fish) are more strongly attracted to algae than they are repelled by walls. More significant variations may appear as a result of a large number of incorrect observations at the beginning of learning, when the learning coefficient is highest (case #5 in the table). These observations show that the agent is indeed capable of inferring the behavioural preferences of another agent.
V Predicting the behaviours of a moving object (ICDL 2025)
Now that the agent can detect a mobile object and knows its behavioural preferences, it becomes possible to predict its most probable future movements. Here, we assume that this other agent will act in a way that maximises the satisfaction derived from its movements, i.e. it will select the movements that will bring it closest to the affordances it considers positive. The different sequences σk, defined in step III, characterise the different future positions of the moving element. We will adapt the equation for the utility of movements (step IV) to define an absolute utility value for a given affordance context, which will be calculated for each future position.

The agent can then determine the position that is most likely to be chosen by the mobile entity as the position with the highest utility. The current model considers only a single prediction. However, nothing prevents the use of more elaborate prediction models based on multiple assumptions.

This prediction is limited to the next step. In order to make longer-term predictions, we propose to convert the sequence characterising the next position into the fictional interaction context that the agent would have observed if the mobile entity were at that predicted position. Since the mobile affordance has been confirmed as present, it will not need to project the whole signature or calculate its certainty of presence, which allows for several simplifications.
The first simplification is based on the fact that we do not need the whole interaction context to characterise the presence of this affordance: a single ‘virtually enacted’ interaction will suffice to characterise its position. We must therefore define, based on a sequence characterising a position, an interaction that best characterises this position. The principle is to project, at each signature projection cycle, only the most probable sub-signature, and from this sub-signature, to project only the interaction with the highest weight (i.e. the interaction that has the greatest impact on the prediction of success or failure). The signature of the interaction related to the mobile affordance is thus projected recursively according to the interaction sequence defining the predicted position. The result is a single interaction whose supposed enaction would best characterise the presence of this affordance at the predicted position.

Once this interaction has been obtained, it can be used for a new detection cycle. The second simplification concerns the detection system: since the affordance is considered as present, it is not necessary to calculate the certainty given by a signature projection: we simply record the projections that contain this interaction, linked with a sufficiently high weight. This yields a new set of sequences, as obtained in step III, but centered on the predicted future position. The detection-prediction cycle can then be repeated recursively to obtain a probable trajectory for the moving entity. The trajectory may differ from the ground-truth trajectory of the moving entity due to differences in sensorimotor capabilities between the agent and the moving entity. However, it provides a general direction and therefore increases the chance of interacting with the entity.

VI Generating behaviours incorporating mobile objects (ICDL 2025)
During the recursive detection-prediction process, the agent may detect a future position in the form of an interaction sequence whose length is the same as the prediction step. These sequences imply that if the agent enacts one of them, the mobile entity will, if the prediction is correct, be in the right position to enable the interaction it affords. These particular sequences are called interception sequences.

The interception sequences can play two roles in the decision model of the agent:
- First, they allow the agent to characterize the position of a mobile affordance without using spatial memory. Indeed, by recording these sequences, the agent can characterize the position of a mobile affordance in its internal model as the set of positions allowing interaction with it, rather than its current position. By updating these sequences, through deleting the first element when enacted, the agent can keep the position of the affordance in memory as long as it follows at least one of these interception sequences, even if it can no longer detect this affordance. It is therefore relevant to maintain a wide variety of interception sequences of different lengths to allow the agent to adapt its behavior according to other elements of the environment.
- Then, these sequences can play a role in decision-making. Decision mechanisms rely on the affordance context provided by the space memory. Each affordance is characterized by a set of Places giving an interaction allowing to get closer to it and a distance in number of minimal interactions to reach it. The sequences of interactions can define Places to characterize the position of a mobile affordance: we use the first interaction and the length of the shortest interception sequences of an affordance. It therefore becomes possible to directly use decision models based on the space memory.
Interception sequences thus form a complement to spatial memory for mobile affordances, by allowing a form of object permanence and by providing information, in the form of Places, on positions allowing to interact with these affordances. The video below shows the agent's behaviors with and without the use of interception sequences (thanks to François Suro for his help in making the video). In this experiment, we define the following satisfaction values for the agent's interactions: move forward: 2, bump: -5, eat: 50, slide: 0, turn right and left: -3. The agent will thus be strongly attracted by edible objects, and weakly repelled by solid objects. It will also be more likely to want to move forward than turn. The selection mechanism is the one described in Part IV.
