Les agents développementaux étudiés pendant ma thèse ont montré qu'il était possible de construire un modèle de l'environnement basé uniquement sur les régularités observées dans l'énaction de schemes sensorimoteurs. Ce modèle, après une certaine période d'apprentissage, devient capable de "représenter" l'environnement proche dans un référentiel égocentré, et de suivre et mettre à jour cette représentation quand l'agent se déplace définissant une forme de permanence de l'objet. L'agent caractérise alors son environnement proche sous la forme d'un contexte d'affordances localisées dans l'espace extra-personnel, qui peut être exploité pour générer des comportements satisfaisant ses principes motivationnels.
Ce mécanisme de mémoire spatiale n'a cependant été étudié que dans des environnements statiques, ou, comme ici, dans des environnements où les déplacements sont prédictibles. Afin de pouvoir interagir avec d'autres agents, un agent développemental doit développer la capacité à détecter ces agents et à prédire le ou les comportements les plus probables pour agir en conséquence. Les travaux présentés ici concernent l'étude de l'émergence de la capacité à prédire le comportement d'un autre agent. Le principe est le suivant : un agent agit en fonction des affordances qui l'entourent. Ainsi, si un agent peut connaître le contexte environnemental du point de vue d'un autre agent, et si il connaît ses préférences comportementales, alors il peut prédire les déplacements les plus probables de cet autre agent. Ce principe repose donc sur l'hypothèse que le modèle comportemental de cet autre agent repose sur des principes similaires à celui de l'agent développemental, l'agent "projetant" son propre fonctionnement sur l'autre agent.

Ce principe nécessite plusieurs étapes de traitement :
- être capable de détecter un objet mobile non prédictible,
- être capable de localiser un objet mobile dans l'espace,
- être capable de suivre un objet mobile sur plusieurs étapes consécutives,
- pouvoir inférer les préférences comportementales de l'objet mobile,
- prédire le ou les comportements probables de l'objet mobile,
- générer des comportements intégrant ces prédictions.
Ces travaux ont été décrits dans une trilogie d'articles présentés aux conférences ICDL 2022, ICDL 2023 et ICDL 2025.

I Détecter un objet mobile dans l'environnement (ICDL 2022)
Nos modèles d'apprentissages reposent sur la capacité à prédire le résultat d'un scheme sensorimoteur (succès ou échec) à partir des schèmes sensorimoteurs précédemment énactés. D'un point de vue extérieur à l'agent, un peut définir l'affordance comme l'élément de l'environnement permettant le succès (ou l'échec) d'une interaction i, la prédiction du résultat de i étant alors défini par les interactions dont l'énaction trahit la présence de cette affordance. Les interactions permettant la prédiction de l'interaction i forment la 'Signature' de i. Cette signature permet de définir, à partir des interactions énactées, la certitude de succès ou d'échec de l'interaction comme une valeur entre 1 (certitude absolue de succès) et -1 (certitude absolue d'échec).
Détecter un objet mobile est une question plus complexe qu'il n'y parait : en effet, l'agent peut détecter la présence d'une affordance, mais si celle-ci se déplace, alors l'interaction échouera. De plus, l'affordance peut afforder l'interaction depuis plusieurs positions, en fonction de son déplacement. Ces particularités font que les mécanismes de signatures utilisés jusqu'à présent échouent à intégrer ces objets dans le modèle de l'environnement de l'agent.
La solution proposée est venue d'une observation sur les certitudes mesurées par les signatures des interactions : si ces certitudes étaient toujours négatives et proche de -1, la présence de l'affordance conduisant la plupart du temps à un échec, le fait que l'interaction ne pouvait réussir que si l'affordance était présente a permis une construction au moins partielle de la signature. Ainsi, la certitude de succès, bien que toujours négative, se révèle systématiquement plus faible en valeur absolue quand l'affordance est présente (typiquement, entre -0.8 et -0.9 quand l'affordance est présente et entre -0.9 et -1 quand elle est absente).
Le principe suivant a alors été proposé : on commence par un apprentissage classique. Après un certain nombre de tests de l'interaction, période pendant laquelle on mesure la prédiction moyenne, on ajoute la règle suivante :
- si l'interaction est un succès, alors on renforce la signature comme un succès,
- si l'interaction est un échec ET la prédiction est inférieure à la moyenne, la signature est renforcée comme un échec,
- si l'interaction est un échec ET la prédiction est supérieure à la moyenne, la signature n'est pas modifiée.
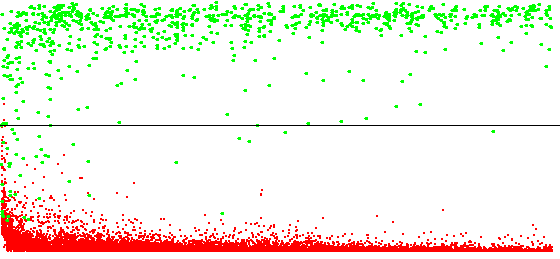
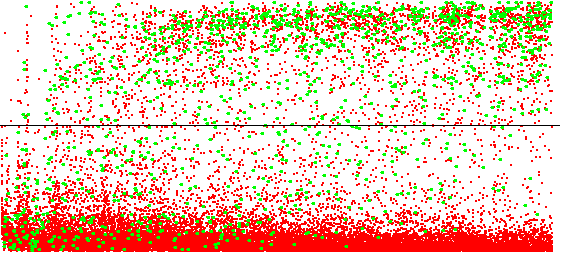
L'élimination des cas d'échec en cas de présence (supposée) de l'affordance permet l'émergence des signatures d'interactions affordées par des objets mobiles. Les figures ci-dessous montrent les profils de prédictions pour des interactions affordées par des éléments statiques et des éléments dynamiques.
Les différents mouvements d'un objet mobile pouvant avoir des probabilités différentes, il est apparu nécessaire de séparer les différents contextes affordant une interaction, c'est à dire les différentes positions à partir desquelles l'interaction peut être énactée. J'ai alors proposé un modèle de signature définissant plusieurs "sous-signatures" en compétition. Après une première phase d'apprentissage où les "sous-signatures" sont renforcées de façon identiques, le système de compétition s'active : en cas de succès de l'interaction, seule la sous-signature avec la certitude la plus élevée est renforcée comme un succès. En cas d'échec, toutes les sous-signatures sont renforcées comme un échec. Ce principe conduit chaque sous-signature à se spécialiser pour un certain contexte affordant l'interaction. Afin d'accélérer le processus de spécialisation, une sous-signature dont les prédictions affichent un certain niveau de fiabilité va éliminer le contexte qu'elle caractérise des autres sous-signatures. La figure suivante montre une implémentation de ce modèle de signature à base de neurones formels.

Lorsqu'une sous-signature affiche un certain niveau de fiabilité, on peut mesurer le ratio de succès et d'échec quand l'affordance est supposée présente. Ceci permet de définir la probabilité (information indépendante de la certitude d'énaction) propre à chaque position de l'objet mobile, et ainsi caractériser la probabilité de chaque déplacement possible.

Au début, l'agent est seulement dirigé par le mécanisme d'apprentissage, qui cherche à tester les interactions dont la certitude de succès/échec est faible (en valeur absolue). Ce n'est que lorsque les signatures commencent à fournir des certitudes élevées que les mécanismes d'exploitation remplacent progressivement le mécanisme d'apprentissage (bien que ce dernier redevienne actif si l'environnement change suffisamment pour rendre les signatures obsolètes).
Les signatures sont implémentées avec des ensembles de 7 neurones formels en compétition. L'agent dispose d'un ensemble de 6 interactions dites primitives : avancer d'un pas, se cogner, manger, glisser sur un objet mou, tourner à gauche et à droite de 90°. Le système visuel permet d'observer trois couleurs (rouge, vert et bleu) à l'une de 15x9=135 positions du système visuel. Ces positions ne sont pas connues de l'agent, et la distribution en grille régulière permet une lecture plus simple des signatures. Le système visuel peut ainsi générer 405 perceptions visuelles. Ces informations ne peuvent pas être dissociées du mouvement qui leur a donné naissance, à savoir le mouvement généré par l'énaction d'une interaction primaire. On associe donc ces perceptions visuelles aux interactions primaires (sauf pour se cogner qui ne génère pas de mouvement) pour former un ensemble de 2025 interactions secondaires. Ces interactions ont donc la forme "avancer et voir un élément bleu en position n°23" ou "tourner à droite et voir un élément vert en position n°64". Ces interactions visuelles secondaires portent à 2031 le nombre d'interactions disponibles pour l'agent.
Afin de faciliter la lecture et l'analyse du contexte d'interactions énactés et des signatures, la liste des interactions est mise en forme de la façon suivante : les six interactions primaires sont représentées en bas par six petits carrés. Les interactions visuelles sont groupées en fonction de leur interaction primaire associée pour former cinq groupes. Dans chaque groupe, les interactions sont organisées pour correspondre à leur position réelle dans le champ de vision, et colorées en fonction de la couleur qui leur est associée. Ces groupes forment ainsi une image en couleur représentant un contexte visuel devant l'agent.
On laisse donc, dans un premier temps, l'agent évoluer dans son environnement (figure ci-dessus) pour découvrir les régularités dans ses interactions et construire les signatures. Les signatures des interactions se cogner et glisser, qui sont affordées par des objets statiques, apparaissent dans les 5000 premiers cycles de décision, durée similaire à ce qui a été observée dans des environnements statiques. Comme ces interactions ne sont affordées que par un unique contexte, un seul des neurones de la signature est exploité, les autres conservant des poids proches de 0. L'interaction se cogner est affordée par la détection d'un objet vert devant l'agent (et ce, quel que soit le mouvement effectué par l'agent), mais également l'énaction précédente de l'interaction se cogner, caractérisant toutes deux la présence d'un mur vert devant l'agent. Cet exemple montre que les signatures peuvent regrouper toutes les modalités sensorielles permettant de caractériser une affordance. L'interaction glisser est associée à l'observation d'un objet rouge devant l'agent, caractérisant la présence d'une algue rouge. Les deux signatures définissent un contexte avec une probabilité supérieure à 90%, confirmant que l'affordance ne se déplace pas.

Les signatures des interactions avancer et manger prennent plus de temps pour émerger : environ 50 000 cycles de décisions sont nécessaires, notamment à cause du fait que l'interaction peut échouer même en présence de l'affordance. On notera que la signature de l'interaction avancer a un poids de sortie W proche de -1 : il s'agit donc d'une interaction dont l'affordance désignée par la signature empêche l'énaction. Dans le cas de l'interaction manger, jusqu'à 5 contextes sont définis, qui correspondent chacun à une position du poisson par rapport à l'agent qui, si le poisson se déplace dans la bonne direction, permet le succès de l'interaction. Notons que le poisson ne pouvant être sous l'agent après un pas en avant, le contexte "below" n'est pas présent sur les trois premières lignes de la signature (groupes d'interactions liées à avancer, manger et glisser). Les contextes caractérisant la présence d'un poisson devant l'agent sont définis avec une probabilité de succès d'environ 25%, tandis que les positions périphériques sont proches de 19%, ce qui est cohérent avec le fait que les poissons puissent être bloqués par un mur. Dans le cas de l'interaction avancer, jusqu'à 7 contextes sont définis. Nous retrouvons les contextes liés à la présence d'un élément vert et d'un élément rouge devant l'agent, définis avec une probabilité élevée indiquant que ces objets sont statiques, et les 5 contextes liées à l'objet bleu (les poissons) avec des probabilités proches de celles définies par la signature de l'interaction manger. Il est ainsi possible de distinguer les objets mobiles et statiques à partir de leurs probabilités.

Les interactions visuelles ont également leurs propres signatures. Dans le cas des interactions visuelles liées aux couleurs vertes et rouges, un seul neurone définit un contexte. En effet, les objets verts et rouges de cet environnement sont statiques. En analysant l'écart entre la position associée à une interaction visuelle, et la position des éléments désignés par sa signature, on se rend compte que la signature encode le mouvement produit par l'interaction primaire. Ainsi, pour l'interaction avancer, la signature désigne un élément de la même couleur, mais situé un pas en avant. Pour l'interaction tourner de 90°, on observe une rotation du champ de vision autour de l'agent.

Les signatures des interactions visuelles liées à la couleur bleue désignent jusqu'à 5 contextes, correspondant aux cinq déplacements possibles des objets bleus. Le mouvement généré par l'interaction primaire reste toutefois visible.

La capacité des signatures à encoder le mouvement d'une interaction primaire est à la base du mécanisme de détection des affordances distantes décrit ci-après.
II Localiser un objet mobile dans l'espace (ICDL 2023)
La localisation des affordances distantes repose sur une propriété des signatures d'interactions : une signature désigne les interactions permettant de détecter une affordance, interactions qui peuvent avoir leur propre signature. Ainsi, si l'on considère les interactions {jk} désignées par une signature d'une interaction i, associées à une même interaction primaire j, alors l'ensemble des signatures de ces interactions désigne un élément qui, après avoir enacté j, est susceptible d'afforder l'interaction i. Ainsi, cette "projection" de la signature désigne l'affordance de i, mais à une position atteignable en énactant l'interaction j. En effectuant cette projection récursivement, il devient possible de désigner une affordance atteignable en effectuant une certaine séquence d'interactions.

Dans le cas d'une interaction affordée par un objet mobile, la signature est constituée de plusieurs sous-signatures. Une projection conduirait à une explosion du nombre de contextes projetés. Nous avons donc proposé d'utiliser les probabilités des sous-contextes pour filtrer et ne conserver que les projections les plus probables. Ce principe de projection est illustré ci-dessous.

Une fois les projections de signatures obtenues, il devient possible de détecter les affordances distantes et de les localiser par le biais de séquences d'interactions. Comme chaque interaction peut être "reliée" par plusieurs séquences, alors une même affordance mobile sera localisée par plusieurs séquence. Ces séquences permettent de caractériser les différentes positions possibles de l'objet mobile à l'instant suivant. La figure ci-dessous montre un exemple de détection d'affordances distantes.

Les affordances statiques, désignées par des sous-signatures avec une forte probabilité, sont localisées par un faible nombre de séquences (parfois même une seule). Ces affordances sont enregistrées par la mémoire spatiale de l'agent. La position de ces affordances est alors caractérisée par une liste de structures appelées Lieux, donnant la distance et la première interaction de la séquence menant jusqu'à l'affordance. Les affordances mobiles sont détectées par un ensemble de séquences caractérisant les différents mouvements possibles. Comme la mémoire spatiale n'a pour le moment jamais été testée avec des affordances mobiles, ces affordances ne seront pas enregistrées.
III Suivre un objet mobile sur plusieurs étapes consécutives (ICDL 2023)
Pour pouvoir analyser le comportement d'un autre agent, il est important de pouvoir reconnaitre ce même agent sur plusieurs pas de simulation et être capable d'observer ses déplacements, notamment par rapport à son environnement immédiat. L'hypothèse est donc que si l'agent développemental peut connaitre le contexte d'affordances d'un autre agent et peut observer ses déplacements, alors il devient possible de déterminer les préférences comportementales de cet autre agent, notamment vers quelles affordances il a tendance à se diriger et quelles affordances il a tendance à éviter.
Cette hypothèse implique deux contraintes particulières. D'une part, l'agent doit disposer d'interactions lui permettant de détecter la présence de toutes les affordances susceptibles d'influer sur le comportement de l'autre agent. D'autre part, l'autre agent doit utiliser un modèle comportemental similaire à ceux de l'agent développemental, de façon à pouvoir, à partir de son propre modèle comportemental, comparer ce que lui aurait fait dans des situations similaires, et, par analyse des différences, déduire les préférences de l'autre agent.
Pour obtenir le contexte du point de vue d'un autre agent, nous exploiterons les propriétés de la mémoire spatiale : cette structure permet de mettre à jour le contexte d'affordance autours de l'agent pendant qu'il se déplace en énactant des interactions. Nous pourrons donc simuler une séquence menant vers une affordance mobile et obtenir le contexte d'affordances "observable" depuis cette position. Il faut cependant résoudre deux problèmes :
- premièrement, une affordance mobile est localisée par un ensemble de séquences d'interaction. Ce problème est facilement résolu par le fait que nous n'avons besoin que de la distance des affordances. Ainsi, il suffit de prendre la moyenne des distances des affordances obtenues en simulant les différentes séquences.
- Ensuite, les séquences d'interaction montrent la position à partir de laquelle on peut interagir avec l'affordance, et non la position de l'affordance elle-même. La solution retenue repose sur les interactions affordés par des affordances "négatives", c'est à dire dont le succès est lié à l'absence de l'affordance. L'hypothèse est que ces affordances négatives délimitent un volume de l'espace qui doit être vide, ce volume devant être occupé, totalement ou partiellement, par l'agent lui-même pendant ou à la fin de l'énaction de cette interaction. L'interaction avancer d'un pas illustre bien ce principe : la signature de cette interaction indique le volume devant l'agent que celui-ci va occuper pendant et après avoir avancé, la présence de tout objet dans ce volume conduisant à l'échec de l'interaction. Sur les versions continues du modèle, la signature désigne un volume de la taille et de la forme de la 'hitbox' de l'agent (forme utilisée par le moteur physique de l'environnement pour gérer les collisions). On exploite ensuite le fait que certaines interactions soient mutuellement alternatives, c'est à dire que l'échec de l'une peut conduire au succès de l'autre. Dans notre exemple, les interactions avancer, se cogner, manger et glisser sont mutuellement alternatives. Si l'une de ces interactions échoue, l'une des trois autres sera énactée à la place. Le fait que deux interactions soient mutuellement alternatives implique que leurs affordances aient une taille et une position similaires. Ainsi, si l'agent détecte la présence de l'interaction se cogner, en supposant qu'il puisse avancer, alors il occuperait la même position que l'objet qui afforde se cogner. Nous retenons donc le principe suivant : si on détecte une affordance distante d'une interaction i localisée par une certaine séquence s, si il existe une interaction j affordée par une affordance négative et qui soit mutuellement alternative de i, alors on peut obtenir la position réelle de l'affordance de i en simulant la séquence [s,j].

Maintenant que le contexte d'affordances de l'entité mobile est connu, il faut pouvoir observer cette entité sur plusieurs pas de simulation pour en étudier le comportement. On utilise pour cela les séquences permettant de localiser l'affordance : certaines de ces séquences commencent par l'interaction que l'agent effectue. Ainsi, il est possible d'obtenir un ensemble de séquences localisant la nouvelle position à l'instant t+1 en filtrant les séquences commençant par l'interaction effectuée et en retirant cette première interaction. Une nouvelle détection permet la détection d'affordances mobiles. Si certaines séquences sont communes entre celles mises à jour et celles nouvellement détectées, alors il est probable que la nouvelle entité soit la même que celle détectée à l'instant t. Une fois l'entité identifiée, on observe les éventuelles variations de distances qui apparaissent dans le contexte d'affordances. Si au moins une affordance a eu une variation de distance proche de 1 (le déplacement étant en théorie d'exactement 1 interaction), alors on peut considérer que l'affordance s'est déplacée. On peut noter que le déplacement est mesuré dans un référentiel allo-centré (puisque reposant sur les éléments statiques de l'environnement), une première pour nos agents développementaux qui jusqu'à présent, n'utilisaient que des référentiels égo-centrés.

IV Inférer les préférences comportementales de l'objet mobile (ICDL 2023)
Ce mécanisme repose sur l'hypothèse que le comportement de l'entité mobile utilise un mécanisme proche de celui de l'agent développemental, afin de pouvoir projeter ce mécanisme de décision sur l'entité. Le modèle est donc limité à la compréhension d'agents dont la complexité ne dépasse pas celle de l'agent développemental, sans quoi celui-ci pourrait ne pas appréhender les causes des actions de l'autre agent. L'idée est ici d'appliquer le modèle décisionnel de l'agent sur l'entité mobile, et d'analyser ses déplacements pour adapter les valeurs de satisfaction des interactions.
Les modèles de décision actuels de nos agents développementaux sont principalement réactifs, et poussent l'agent à se rapprocher des affordances d'interactions avec une valeur de satisfaction élevée, et rester éloigner des affordances d'interactions avec une valeur de satisfaction négative. Ces modèles définissent une valeur d'utilité aux interactions permettant de se rapprocher des affordances "intéressantes", qui conditionne le choix de l'interaction à énacter.

L'agent développemental ne peut pas connaitre les interactions de l'entité mobile. En revanche, on peut supposer que, quel que soit le déplacement effectué par cette entité, son mouvement doit le rapprocher d'affordances "positive" ou l'éloigner d'affordances "négatives". On peut donc définir une valeur d'utilité non pas aux interactions, mais au changement de position de l'entité. L'utilité doit en temps normal être toujours positive, l'agent étant supposé suivre ses préférences.

Ainsi, si la valeur d'utilité entre deux pas consécutifs est négative, c'est que les préférences ne sont pas correctes et doivent être modifiées. En cas de correction, on applique le principe suivant : les interactions des affordances qui se rapprochent voient leur valeur de satisfaction augmenter, tandis que les interactions des affordances qui s'éloignent voient leur valeur de satisfaction diminuer. La variation de valeur dépendra de la distance d'une affordance, les affordances proches ayant normalement plus d'influence sur le comportement. afin de réduire l'impact d'observations incomplètes du contexte d'affordances, on ajoutera les règles suivantes :
- La correction des valeurs ne peut se faire que si les contextes avant et après le mouvement contiennent les mêmes affordances : l'apparition ou la disparition d'une affordance pouvant fausser les calculs de l'utilité.
- La correction sera inversement proportionnelle à la distance de l'entité : une entité éloignée aura plus de chance de percevoir des affordances non visibles par l'agent.
- La correction devient de plus en plus faible avec le temps : ceci permet de stabiliser progressivement les valeurs de satisfactions et de réduire l'impact d'une observation incomplète du contexte d'affordances.
L'environnement de test a été modifié pour tester l'inférence des valeurs de satisfaction. Les poissons sont désormais contrôlés par un mécanisme de décision qui dépend des objets qui l'entourent. Comme la version actuelle de la mémoire spatiale n'intègre pas les éléments mobiles, nous ne pourrons tester que l'inférence des valeurs de satisfaction liées à des objets statiques. Un poisson est fortement attiré par les algues (qu'il mange quand il passe sur l'une d'elles) et faiblement repoussé par les murs. La valeur de satisfaction des algues est fixée à 20 et celle des murs, à -2. Le fait que les poissons réagissent aux algues a motivé l'ajout de l'interaction 'glisser' dans l'ensemble d'interactions de l'agent développemental. Sans cette interaction, l'algue, qui est traversable, est pour l'agent comparable à un espace vide. L'agent n'aurait alors pas été en mesure de déterminer les causes des décisions des poissons. Le fait qu'un agent ait besoin de pouvoir détecter les affordances d'autres agents est une contrainte forte, mais biologiquement plausible dans le cas d'un prédateur évoluant dans le même environnement que ses proies.

Pour cette expérience, l'agent est équipé d'une mémoire spatiale pré-câblée reproduisant les principes de fonctionnement observés durant mes travaux de thèse, afin de s'affranchir de tout biais liés à un apprentissage incomplet de cette structure. Un mécanisme de curiosité est implémenté, qui pousse l'agent à se diriger vers l'affordance détecté comme mobile la plus proche, multipliant les chances d'observations pertinentes et fiables. Ce mécanisme exploite les séquences d'interactions menant à ces affordances, en sélectionnant la première interaction de ces séquences. En cas d'observation d'une utilité négative avec un contexte d'affordances cohérent (mêmes affordances), les valeurs de satisfactions d'une affordance pour un élément mobile sont mise à jour de la façon suivante :

Les valeurs se stabilisent rapidement, moins de 500 observations et mises à jour des valeurs sont nécessaires. Le tableau ci-dessous montre un échantillon représentatif de tests et les valeurs obtenues. Notons que comme on ne cherche à connaitre que le signe de la valeur de l'utilité, et que les positions sont comparées entre elles, les valeurs de satisfaction peuvent être multipliées par n'importe quelle constante positive. Aussi, seuls les signes et le rapport entre les valeurs de satisfaction sont importants.

Nous pouvons observer que l'agent définit systématiquement une valeur positive concernant les éléments qui affordent l'interaction glisser et une valeur négative pour les éléments qui affordent l'interaction se cogner. D'autre part, le ratio entre ces deux valeurs dépasse rarement de l'intervalle [-20,-5], montrant que ces affordances mobiles (poissons) sont plus fortement attirées par les algues qu'elles ne sont repoussées par les murs. Des variations plus importantes peuvent apparaitre à la suite d'un grand nombre d'observations incorrectes au début de l'apprentissage, quand le coefficient d'apprentissage est le plus élevé (cas n°5 dans le tableau). Ces observations montrent que l'agent est bien capable d'inférer les préférences comportementales d'un autre agent.
V Prédire le comportement de l'objet mobile (ICDL 2025)
Maintenant que l'agent peut détecter un élément mobile et en connaitre les préférences comportementales, il devient possible de prédire quels seront ses futurs déplacements les plus probables. Nous prenons ici l'hypothèse que cet autre agent va agir de façon à maximiser la satisfaction induite par ses déplacements, c'est à dire qu'il va sélectionner les mouvements qui vont lui permettre de se rapprocher le plus d'affordances qui lui semblent positives. Les différentes séquences σk, définies à l'étape III, caractérisent les différentes positions futures de l'élément mobile. Nous allons adapter l'équation de l'utilité des déplacements (étape IV) pour définir une valeur d'utilité absolue à un contexte d'affordance donné, qui sera calculée pour chaque position future.

L'agent peut ensuite déterminer la position qui a le plus de chances d'être choisie par l'entité mobile comme la position avec l'utilité la plus élevée. Le modèle actuel ne considère qu'une seule prédiction. Cependant, rien n'interdit des modèles de prédiction plus élaborés reposant sur plusieurs hypothèses.

Cette prédiction reste limitée à l'étape suivante. Pour pouvoir effectuer des prédictions à plus long terme, nous proposons de convertir la séquence caractérisant la prochaine position en un contexte d'interaction fictif, tel que l'agent l'aurait observé si l'entité mobile se trouvait à cette position prédite. Etant donné que l'affordance mobile a été confirmée comme présente, il ne sera pas nécessaire de projeter l'ensemble de la signature, ni de calculer sa certitude de présence, ce qui permet de nombreuses simplifications.
La première simplification repose sur le fait que nous n'avons pas besoin du contexte d'interaction permettant de caractériser la présence de cette affordance : une seule interaction "virtuellement énactée" suffira à caractériser sa position. Nous devons donc définir, à partir d'une séquence caractérisant une position, une interaction susceptible de caractériser au mieux cette position. Le principe retenu est de projeter, à chaque cycle de projection de la signature, seulement la sous-signature la plus probable, et de cette sous-signature, ne projeter que l'interaction avec le poids le plus élevé (donc l'interaction qui a le plus d'impact sur la prédiction de succès ou d'échec). On projette ainsi récursivement la signature de l'interaction liée à l'affordance mobile selon la séquence d'interaction définissant la position prédite. Le résultat est une interaction unique dont l'énaction supposée permettrait de caractériser au mieux la présence de cette affordance à la position prédite.

Une fois cette interaction obtenue, elle peut être utilisée pour un nouveau cycle de détection. La seconde simplification concerne le système de détection : comme l'affordance est considérée comme présente, il n'est pas nécessaire de calculer la certitude donnée par une projection de signature : on relève simplement les projections qui contiennent cette interaction avec un poids suffisamment élevé. On obtient ainsi un nouvel ensemble de séquences, comme obtenues à l'étape III, mais centrées sur la position future prédite. Le cycle de détection-prédiction peut alors recommencer, et de façon récursive pour obtenir une trajectoire probable de l'entité mobile. La trajectoire peut différer de la trajectoire réelle de l'entité mobile, du fait des différences en terme de possibilités sensorimotrices entre l'agent et l'entité mobile. Cependant, elle permet de donner une direction globale et donc une plus grande chance d'interagir avec l'entité.

VI Générer des comportements intégrant les objets mobiles (ICDL 2025)
Pendant le processus de détection-prédiction récursif, il arrive que l'agent détecte une position future sous la forme d'une séquence d'interaction dont la longueur est la même que l'étape de prédiction. Ces séquences impliquent que si l'agent parcourt l'une d'elle, l'entité mobile sera, si la prédiction est correcte, à la bonne position pour permettre l'interaction qu'elle afforde. Ces séquences particulières sont appelées séquences d'interception.

Les séquences d'interception peuvent jouer deux rôles dans les modèles décisionnels de l'agent :
- d'une part, elles permettent de caractériser la position d'une affordance mobile, sans utiliser la mémoire spatiale. En effet, en relevant ces séquences, l'agent peut caractériser la position d'une affordance mobile dans son modèle interne comme l'ensemble des positions permettant d'interagir avec elle, plutôt que sa position actuelle. En mettant à jour ces séquences, par suppression du premier élément, l'agent peut garder en mémoire la position de l'affordance tant qu'il suit au moins l'une de ces séquences, et ce, même si il ne peut plus détecter cette affordance. Il est donc pertinent de conserver une grande variété de séquences d'interception de différentes longueurs pour permettre à l'agent d'adapter son comportement en fonction des autres éléments de l'environnement.
- D'autre part, ces séquences peuvent jouer un rôle dans la prise de décision. Les mécanismes de décisions reposent sur le contexte d'affordances fournis par la mémoire spatiale. Chaque affordance est caractérisée par un ensemble de Lieux donnant une interaction permettant de s'en rapprocher et une distance en nombre d'interactions minimales pour l'atteindre. Les séquences d'interactions peuvent définir des Lieux pour caractériser la position d'une affordance mobile : on utilise la première interaction et la longueur de la ou des plus courtes séquences d'interception d'une affordance. Il devient donc possible d'utiliser directement les modèles de décisions reposant sur la mémoire spatiale.
Les séquences d'interception forment ainsi un complément à la mémoire spatiale pour les affordances mobiles, en permettant une forme de permanence de l'objet et en fournissant des informations, sous forme de Lieux, sur les positions permettant d'interagir avec ces affordances. La vidéo ci-dessous montre les comportements de l'agent avec et sans l'utilisation des séquences d'interception (merci à François Suro pour son aide dans la réalisation de la vidéo). Dans cette expérience, nous définissons les valeurs de satisfaction suivantes aux interactions de l'agent : avancer : 2, se cogner : -5, manger : 50, glisser : 0, tourner à droite et à gauche : -3. L'agent sera ainsi fortement attiré par les objets comestibles, et faiblement repoussé par les objets solides. Il aura aussi plus tendance à vouloir avancer que tourner. Le mécanisme de sélection est celui décrit dans la partie IV.
